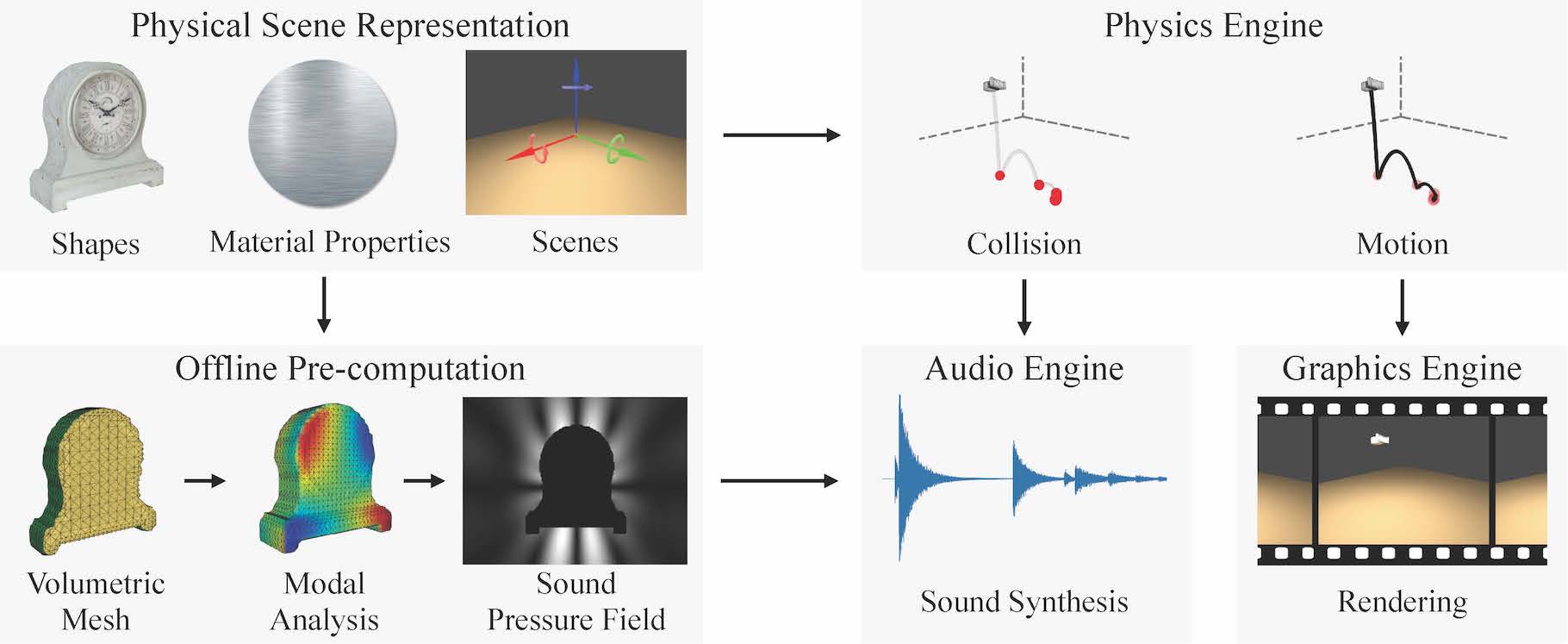
Figure 1: Our pipeline for synthesizing audio-visual data
Abstract
Humans infer rich knowledge of objects from both auditory and visual cues. Building a machine of such competency, however, is very challenging, due to the great difficulty in capturing large-scale, clean data of objects with both their appearance and the sound they make. In this paper, we present a novel, open-source pipeline that generates audio-visual data, purely from 3D object shapes and their physical properties. Through comparison with audio recordings and human behavioral studies, we validate the accuracy of the sounds it generates. Using this generative model, we are able to construct a synthetic audio-visual dataset, namely Sound-20K, for object perception tasks. We demonstrate that auditory and visual information play complementary roles in object perception, and further, that the representation learned on synthetic audio-visual data can transfer to real-world scenarios. By making this generative model near real-time, we are able to conduct analysis-by-synthesis style inference which aims to recover the latent variables that could best reproduce the input audio. We also investigate how past experience and coarse information could further help such inference. Our inference algorithm is able to match human's performance on a set of perception tasks and also makes similar mistakes as humans do.